2026-02-24
Improving Observation Space and Headless Mode
I wanted to write more about my reinforcement learning experiments with Unreal Engine's Learning Agents plugin. And also wanted to complement my previous post with some more details. Please check my previous post if you have not read it yet or need a refresher.
Let's visit BP_SportsCarInteractor blueprint again and open SpecifyAgentObservation function. We will see that the agent only observes its velocity and only a single point on the spline. In this case, the point on the spline and the velocity of the car is part of the agent's environment. It is also mentioned in Sutton&Barto's RL book, that it may be sometimes confusing what is environment and what is not. For instance, velocity is part of the car's environment because the agent cannot directly control its velocity but only influence it with throttling, braking and steering.
The capabilities of the driving agent in the first iteration was already impressive for me but when I watched the agents for some time I could see the janky, fidgety driving. The reason for that is the car agent only observes one point on the track ahead of it. The tutorial nicely addresses this by adding 6 more observation points, 5 meters apart, on the spline ahead of the car. With this observation space, the agent drives smoother and faster as you can see in the video below.
I tried to come up with interesting ideas to improve observation space. I thought about adding distance to the borders of the track but then I realized the track has the same width everywhere and this is not useful. Then I thought about adding progress on track as an observation but that would mean that the agent would memorize the track and would not be able to generalize to other tracks. In the end I decided to play with the number of points on the spline and the distance between them. The results are pretty interesting. In the image below you can see training runs with several different observation spaces.
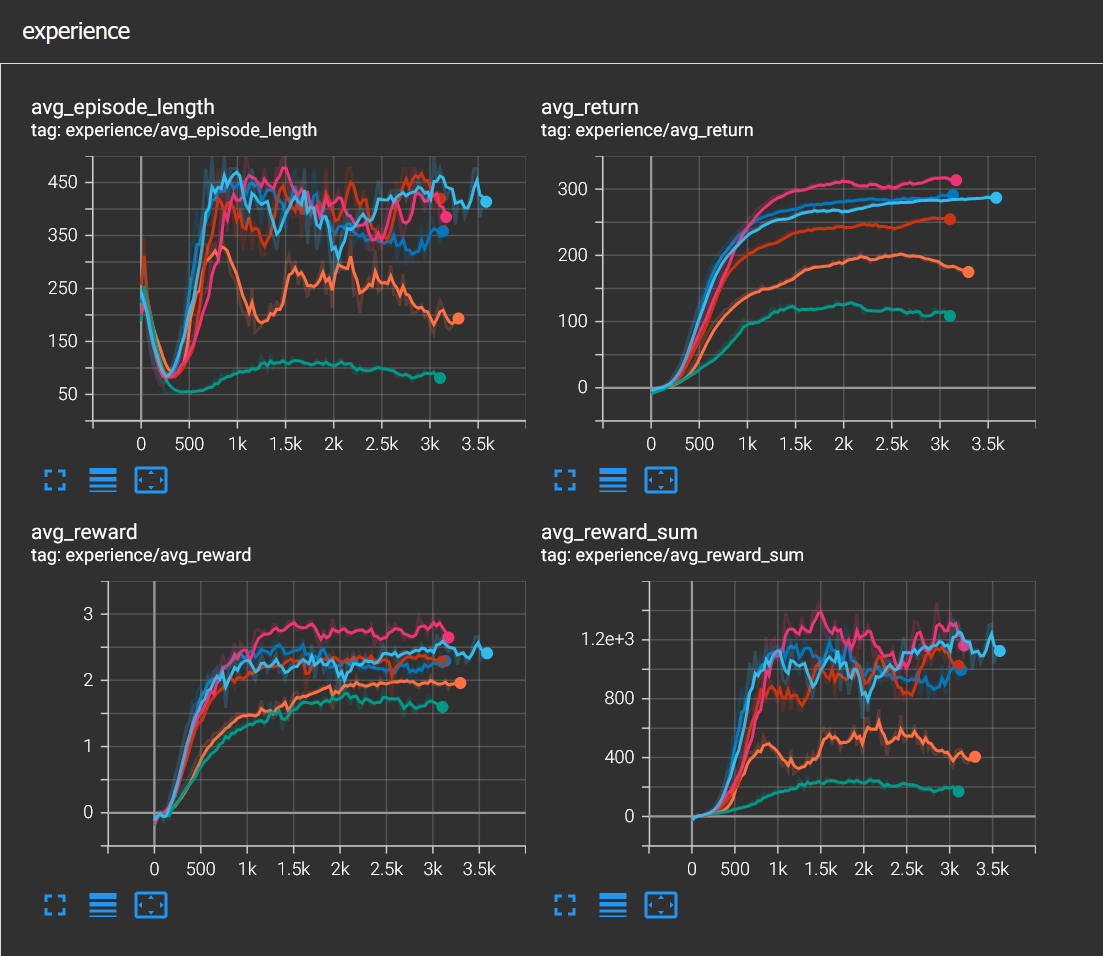
- Pink: 13 points 5 meters apart
- Blue: 7 points 5 meters apart
- Cyan: 13 points 2 meters apart
- Red: 7 points 2 meters apart
- Orange: 1 point only
As you can see from the graphs, I realized that the further the agent sees, the better it drives, so to prove that I added another observation space, this time;
- Green: 2 points 100 meters apart
but it didn't turn out as I expected, the car mostly drove fine but kept crashing into the wall at certain corners and performed much worse than the observation space with only 1 point.
The environment setup, what is observed and what is not have a huge impact on the result of the agent's behaviour.
Headless Mode
It is really important to mention the headless mode since these agents take a very long time to train in Unreal editor. Running the training in headless mode was 4 times faster than training in the editor on my computer. Headless mode is explained in the tutorial and is pretty straight-forward but how to use snapshots is not clear.
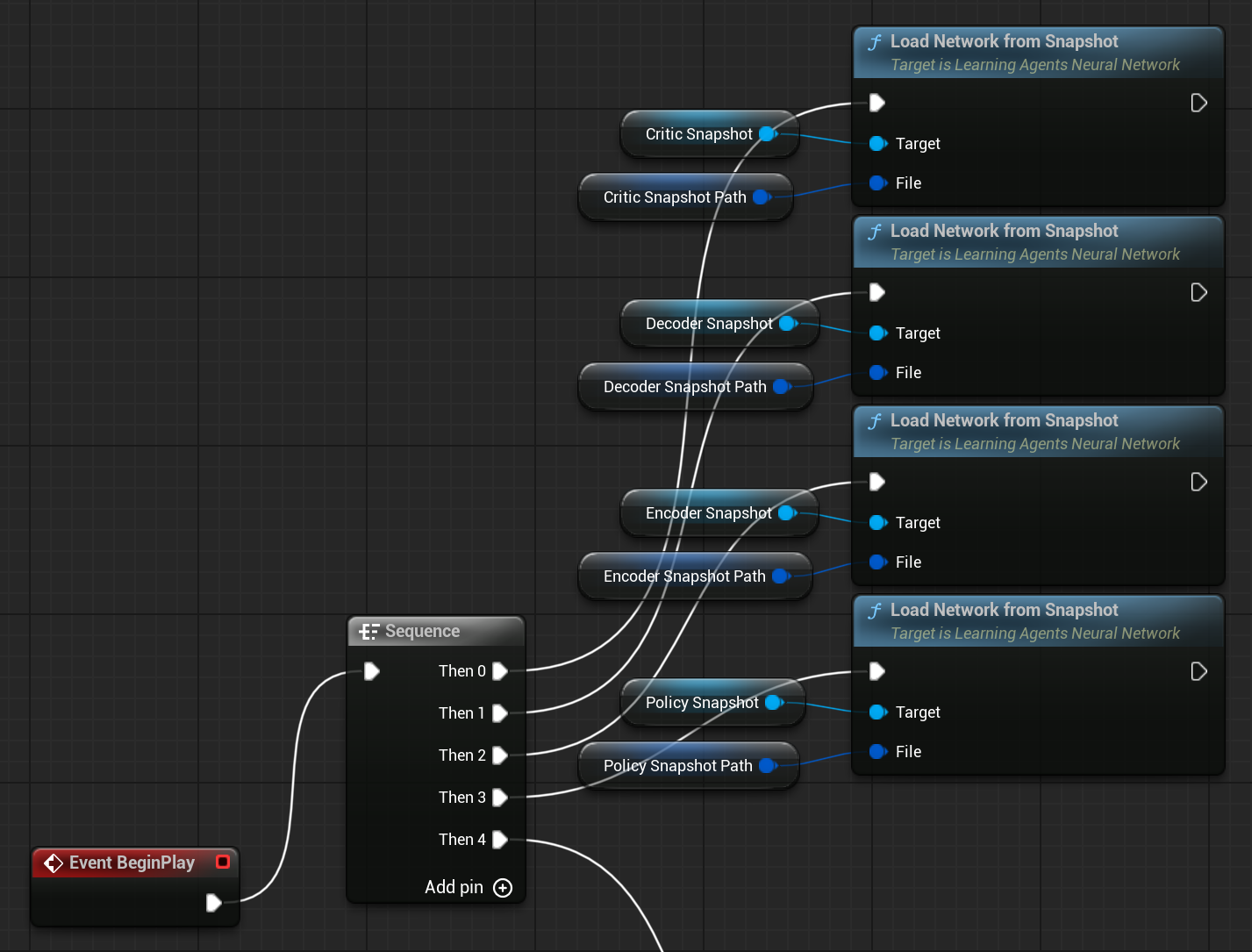
Enabling snapshots in trainer settings enables you to save snapshots of Encoder, Decoder, Policy and Critic networks every 1000 steps by default. This way you can compare different observation spaces or the same space with incremental step count easily. I edited BP_SportsCarManager to load the snapshots.
You can download this project from using this link.
What's Next
I'll try to extend this post with these ideas soon or maybe write part III. Adaptive Observation Spacing: Instead of fixed distances between spline observation points, dynamically adjust the spacing based on track curvature at the car's current position. On tight curves, points are close together for precision. On straights, points spread further apart for lookahead. The observation vector size stays the same, but information density adapts to what's useful.
Line of Sight Raycast: Cast a ray from the car along the spline and measure how far it travels before the track curves out of sight. Use this distance to dynamically set the lookahead range of observation points. The agent's effective vision emerges naturally from track geometry, generalizes to any track shape, and requires no manual tuning.
