2026-03-14
Teaching an AI to Play Kaboom
I was looking for a simple game to create in Unreal Engine and train agents for it from the beginning to understand observation, reward and action spaces better. I found Kaboom! for Atari 2600 from the early '80s. I think it is simple enough for starters and also easy to create some variety. In the original game the goal is preventing bombs hitting the ground. You start with 3 buckets positioned over each other. If you miss a bomb you lose a bucket and when you lose all your buckets, the game is over. I simplified even this simple game. Just added an agent that goes from one side to the other and then added falling objects. The goal of the agent was catching all the falling objects.
Designing Action and Reward Spaces
I started with a discrete action space: just go either left or right. Then I added falling objects. It was very sparse at first and the agent had trouble learning. I increased the frequency and speed of the falling objects. And the agent observed only the closest object to it. Another important point is that dense rewards are much better then sparse ones. Instead of punishing the agent for missing the cloesest object, I punished it for every object hitting the ground. The agent also observed its distance to the left and right borders. With all these observations and rewards, the agent was still not learning. I found a bug in the blueprint that the closest object distance was reset before being read and always zero. The funny thing is, the whole time I was watching the agent: my brain wanted believe that there was some intention to the movements of the agent. It was completely random. I fixed the bug and then I could see that the agent started moving with intention, for real this time. I think this is why it is so very important to use TensorBoard so that you can see for real if your agent is converging and getting smarter in the environment. Don't trust your eyes.
The learning speed and the skill of the agent was not great. The agent was observing too much and not allowed to act properly. When you observe too much, the network has to learn that certain inputs carry zero useful information, which wastes capacity and training time. They dilute the signal, the gradient from meaningful observations (bomb position) gets spread thinner across more inputs. They slow convergence: more inputs = larger network needed = more steps to train.
So I first removed the border observations and just clamped the agent's position in the world. It helped a lot. I also added a small penalty each tick which created urgency. The agent could play now but it was very shaky. I then changed the discrete actions for movement to a continuous one. Instead of just left or right, I changed it to a number between -1 an 1. Negative values for moving left, positive values for moving right. And 0 to stay stationary. The previous agent was not even able to stay stationary. The final reward space was shaped like this:
- Collect a bomb and gain 1.0 reward
- Miss a bomb and gain -0.5 reward
- And on every update, gain -0.001, as I said this creates some urgency for the agent for not taking actions
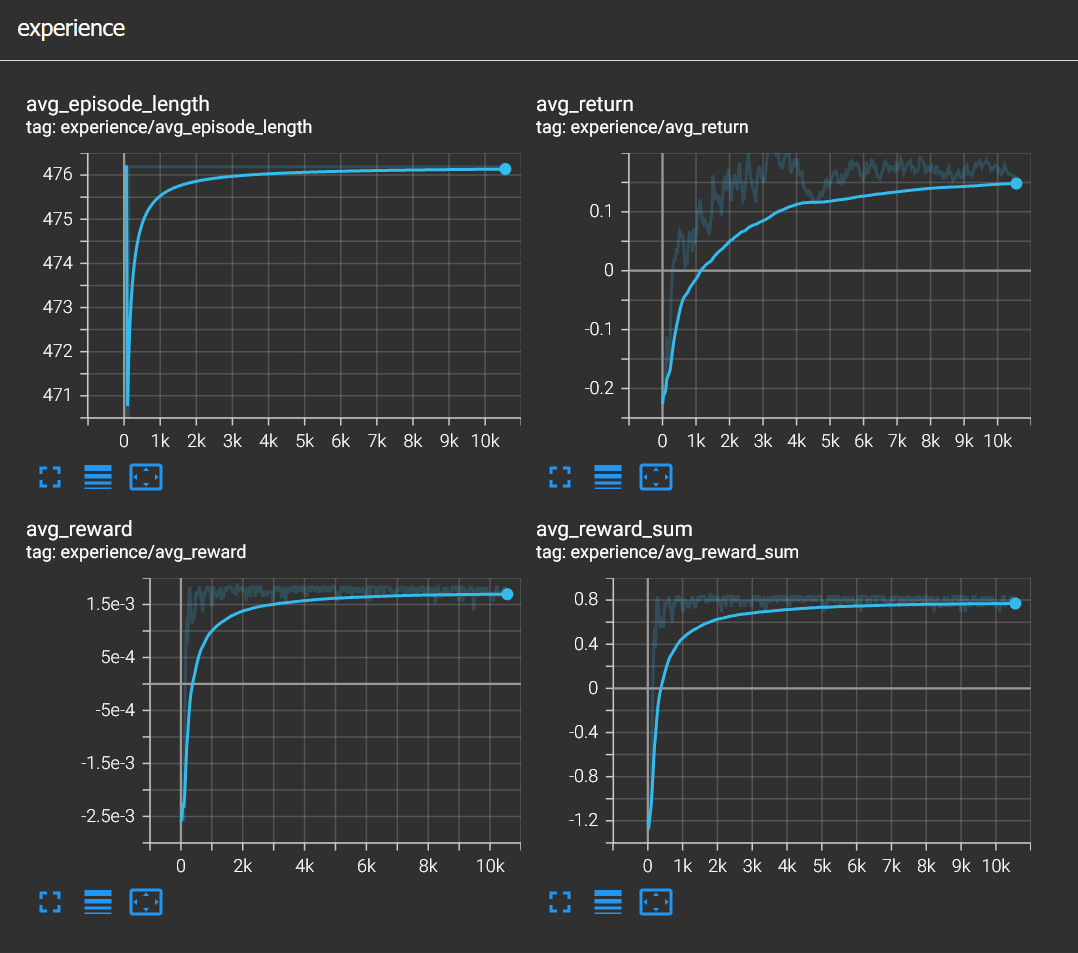
With these parameters the agent converged successfully and after around 3000 steps it was quite confident.
As you can see in the video, the agent has developed a weird behaviour though. It tends to slide to the left side before confidently catching the bomb. Apparently this is analogous to humans having rituals or charms. The agent incorrectly associated that action with the reward of catching a bomb even though it has no effect on it whatsoever.
Then I decided to just revert the rewards to see if it can learn to avoid the objects and I call this game Reverse Kaboom. The agent successfully learned to play it too. The reward space for Reverse Kaboom was like as follows:
- Hit a bomb and gain -1.0 reward
- Gain 0.5 reward for each bomb hitting the ground
- And on every update gain 0.001 reward, a small reward for surviving an update
Similarly the agent for Reverse Kaboom succesfully converged after around 3000 steps. This time the agent had a different quirky behaviour which I was expecting actually. It liked to camp in the corners. I think a human player would do the same in this case since the game does not really reward moving much and the object density is quite low.
While writing this and doing more experiments I realized that there was yet another bug in my implementation, the movement was frame dependent meaning it was running at different speeds in the editor and in headless mode. Even though it learned to play both Kaboom and Reverse Kaboom successfully, fixing the issue actually made the agent converge faster. I'm not sure why but I think what I thought was good for the agent in the editor was not good for it in headless mode, since the movement dynamics are completely different.
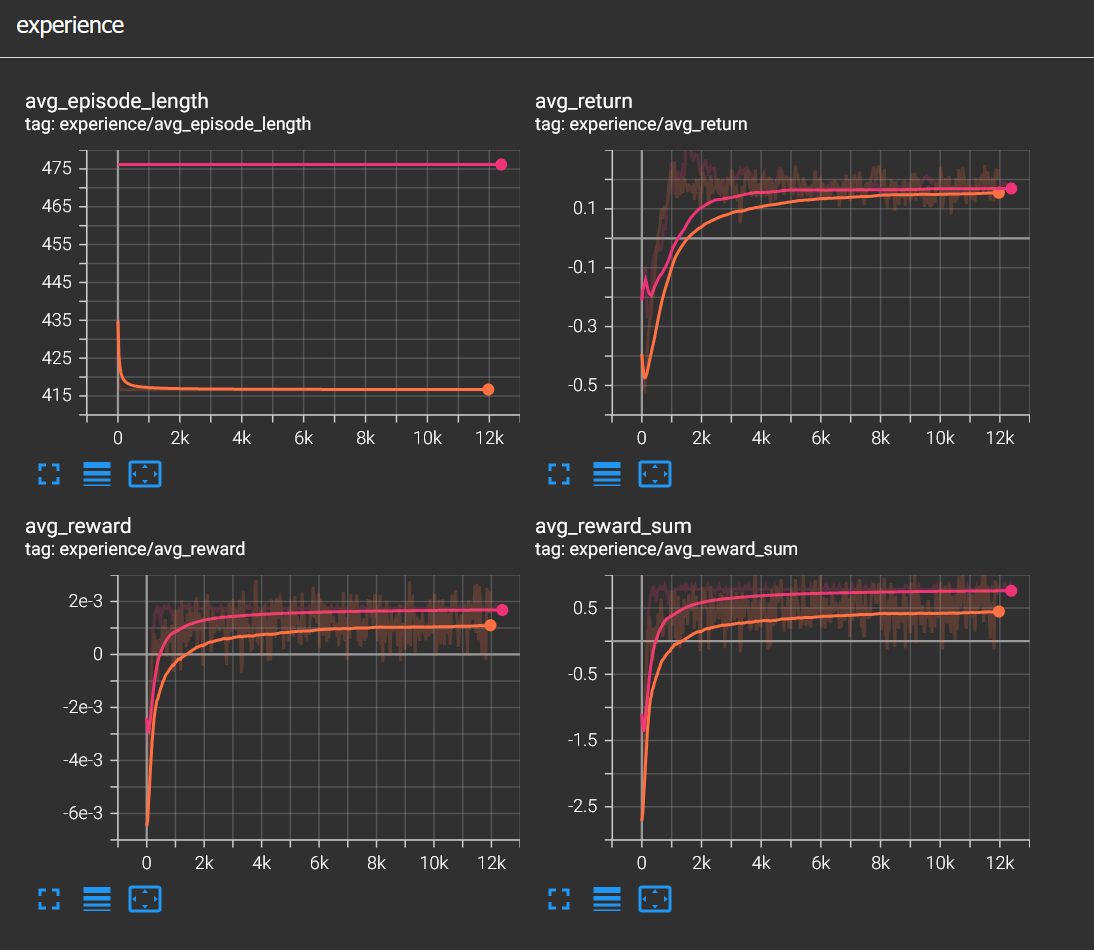
In the image above, orange color represents the buggy agent and pink color represents the fixed one. You can see in all reward graphs that the agent learned the game faster. Fixing and seeing the improvements motivated me to make things a little bit juicier. I increased falling speed and spawn rate of the. Even though the agent only observesthe the closest obstacle, it still managed to survive in this hostile environment.
There is so much to explore in this little game and I'll definitely keep doing that. I have so many ideas but time is the only real constraint. Thank you for reading and let me know if you find stuff that is incorrect.
You can find the source files in this github link.
