2026-04-02
Making an RL Agent Look Good
Since the last post, I've been playing around with the Kaboom example, a lot! I increased obstacle spawn frequency, made obstacles faster and even added collectibles. All of that worked to a degree but there was something that bothered me a lot. First of all the agent's movement was jerky. Even though it was smart and made incredible stunts at times, other times it just ran into the obstacles or just missed the juicy collectible next to it. Seeing those happen during inference is really painful. I wanted to make something that is polished and stable enough to go in a game. You can see agent from the previous post and it certainly cannot go in a game.
I've spent a lot of time on research and reading. As I kept training agents I realized that I needed to improve my workflow otherwise I would lose so much time during training. When the agent gets more complex, the time for training also grows. And there were many times the headless run was corrupted and failed. I was already saving snapshots, so the natural next step was just being able to load the snapshots and continue training from there. And then I changed the environment, contained it in a blue print to be able to run many of them in parallel. In my setup now I can run 64 agents in parallel. This alone cut the training time in half and it does not only make training faster but it also provides the network data from 64 different agents simultaneously, making the experience diverse enough that degenerate single strategies are harder to lock in. I also seeded the random generators in the code so that I get the same random numbers every time. I noticed that there was significant difference when the same network run multiple times.
These improvements gave me a good starting point. I could now start training, do the dishes, come back and check the results and if anything failed, I could return to a previous snapshot which I saved every 1000 steps and continue from there.
The Sentinel
Training an agent to accomplish a certain task and training it to be elegant and graceful are totally different things. In my simple RL experiments, I was able to train an agent that can avoid obstacles in just 1000 steps. But when I wanted to make it smooth things went south really fast. I first started with improving the observation space. I increased observed obstacle count from 1 to 3 and later to 6. To observe multiple obstacles I sorted them by the their Euclidian distances to the agent and provided horizontal and vertical distances separately. Having more observations definitely helps but it also increases training time. Fortunately I was saved by being able to run agents in parallel. I also added a termination rule which didn't exist before. The new rule was if the agent got hit 3 times, it was out. But the real breakthrough came after I fixed the sentinel values. Neural networks work best with normalized values. In my simulation the agent is always at z=0.0 and obstacles spawn at z=600.0. Instead of passing the distance in absolute UE units, I normalize them.
// Step 1: normalize to [0, 1] normalized = absolute_distance / max_distance // 1.0 when spawned, 0.0 at ground // Step 2: invert so the value increases as the obstacle approaches normalized = 1 - normalized // 0.0 when spawned, 1.0 at ground
But this meant if there was no obstacle, both horizontal and vertical observations for that slot were 0. From the agent's perspective this meant that there was always an obstacle hanging at top center of the map. To fix this you need to assign a value that is typically not in the normalized range. That is the sentinel value. Sentinel value is similar to null for observation value. So instead of the calculated 0 value, I set it to 2 for slots that were currently empty. 2 is arbitrary here, the important thing is having a value outside normalized range. I think this was also the solution to the agent always camping in the corners. I assume that previous values were pushing the agent to the sides.
Then with all improvements I started training again. In the image below you can see a total of 60k training steps.
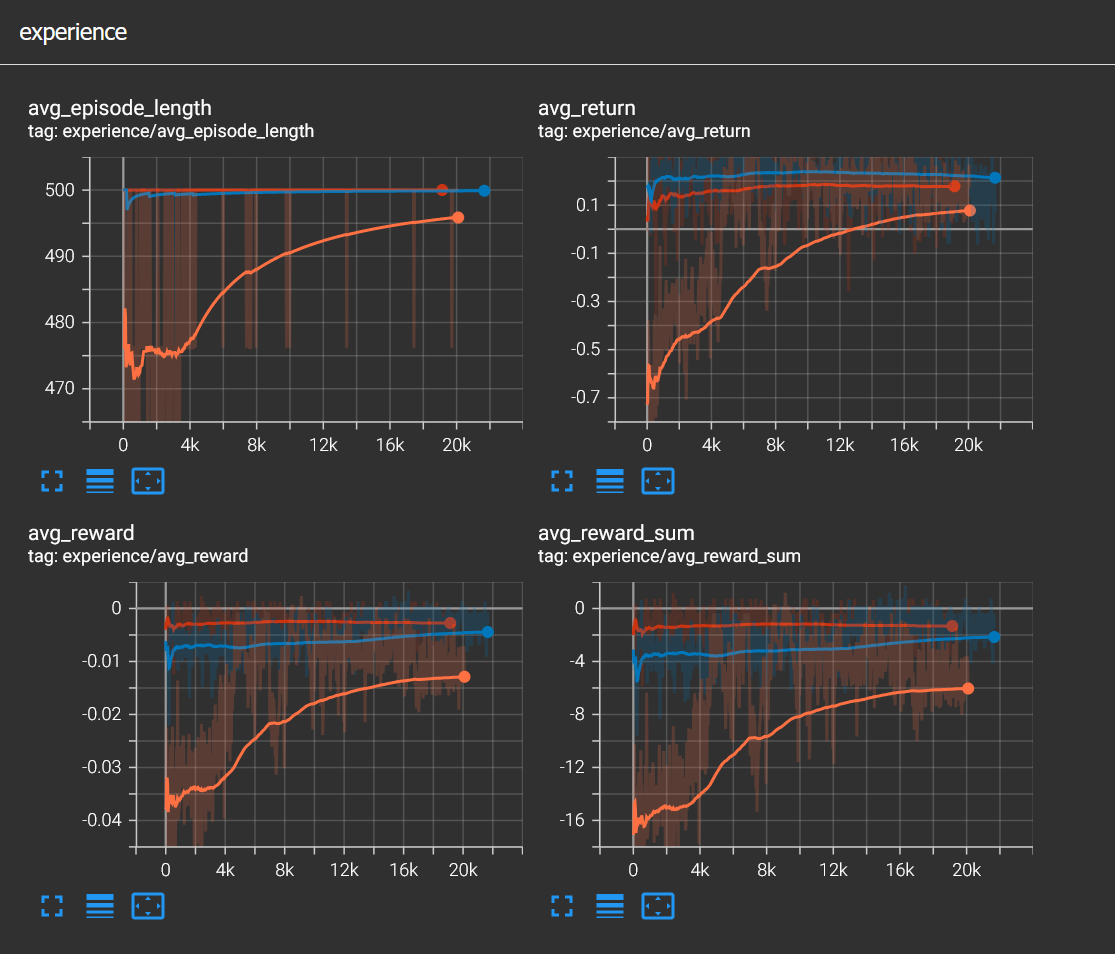
- Orange: From 0 to 20k, the agent slowly learned to avoid obstacles
- Blue: From 20k to 41k, the agent was still improved but not much, you can see that episode lenght is at 500
- Red: From 41k to 60k, I think this was not necessary since the agent stayed the same
This was a good run but there was more to improve. I was not really sure about the miss reward, the 1.0 reward I gave every time an obstacle touched the ground, meaning the agent successfully avoided it. I removed it and the agent did not care. Because the -10.0 reward for getting hit is more than enough to avoid obstacles. Miss reward was just noise for the network.
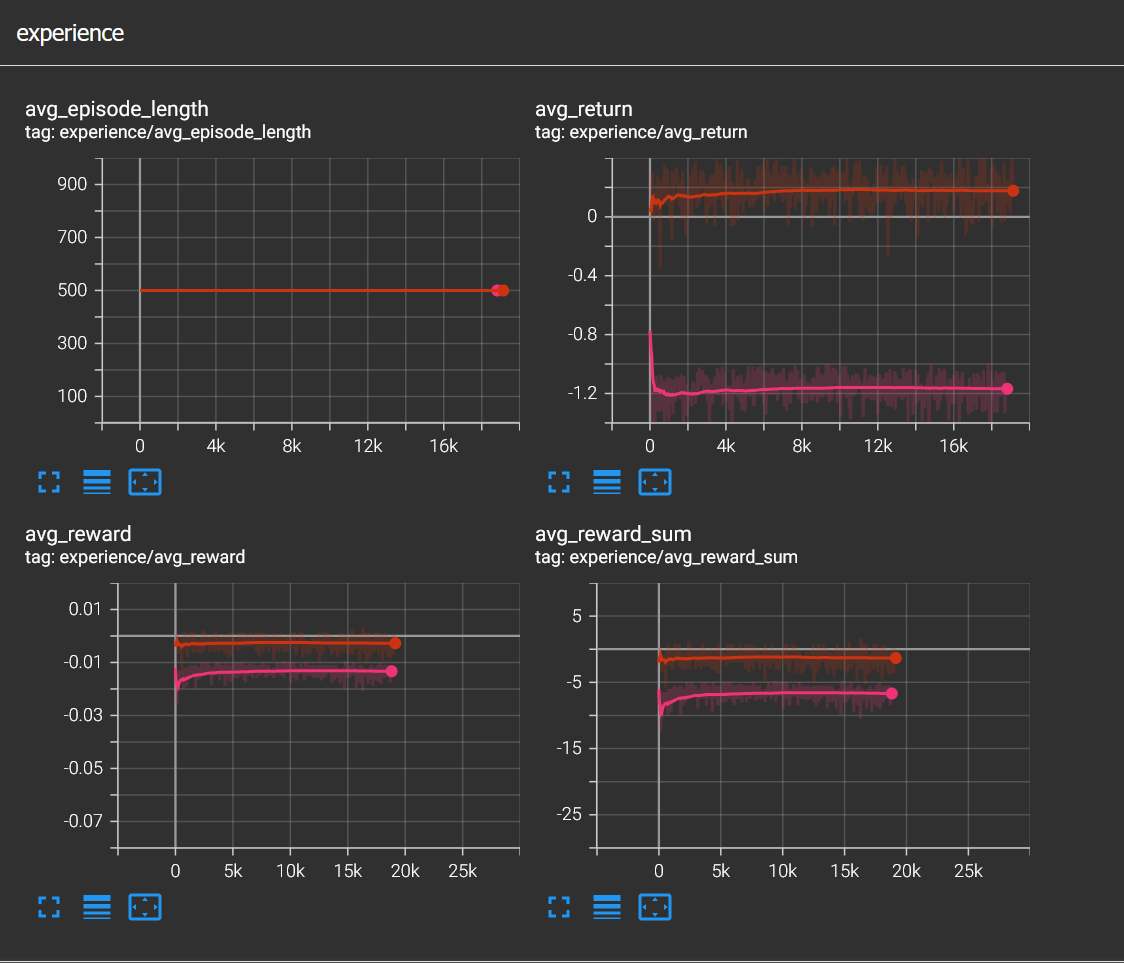
Here I removed miss reward, and continued from 60k steps, the agent was completely fine. Even though average return fell down, episode length was a solid 500. inference was the same, this tells that miss reward was just noise for the agent
Curriculum Learning
While cycling to the rowing club and simultaneously thinking about RL, I realized I might improve agent behaviour by introducing difficulty gradually. Not to brag but I basically rediscovered a concept called Curriculum learning, which is an established method in RL. Honestly there is nothing to brag since this is only natural progression.
Curriculum learning is basically having a difficulty curve for the training environment. Similar to how a human player would be overwhelmed if they started playing a game from the final level, an RL agent is no different. Curriculum learning fixes this problem by slowly increasing difficulty. This can be like making an existing task harder, for instance in my case increasing the frequency of obstacle or it can be adding a new task like collecting coins while avoiding obstacles. For example I lowered the termination rule limit gradually and this is also an example for curriculum learning.
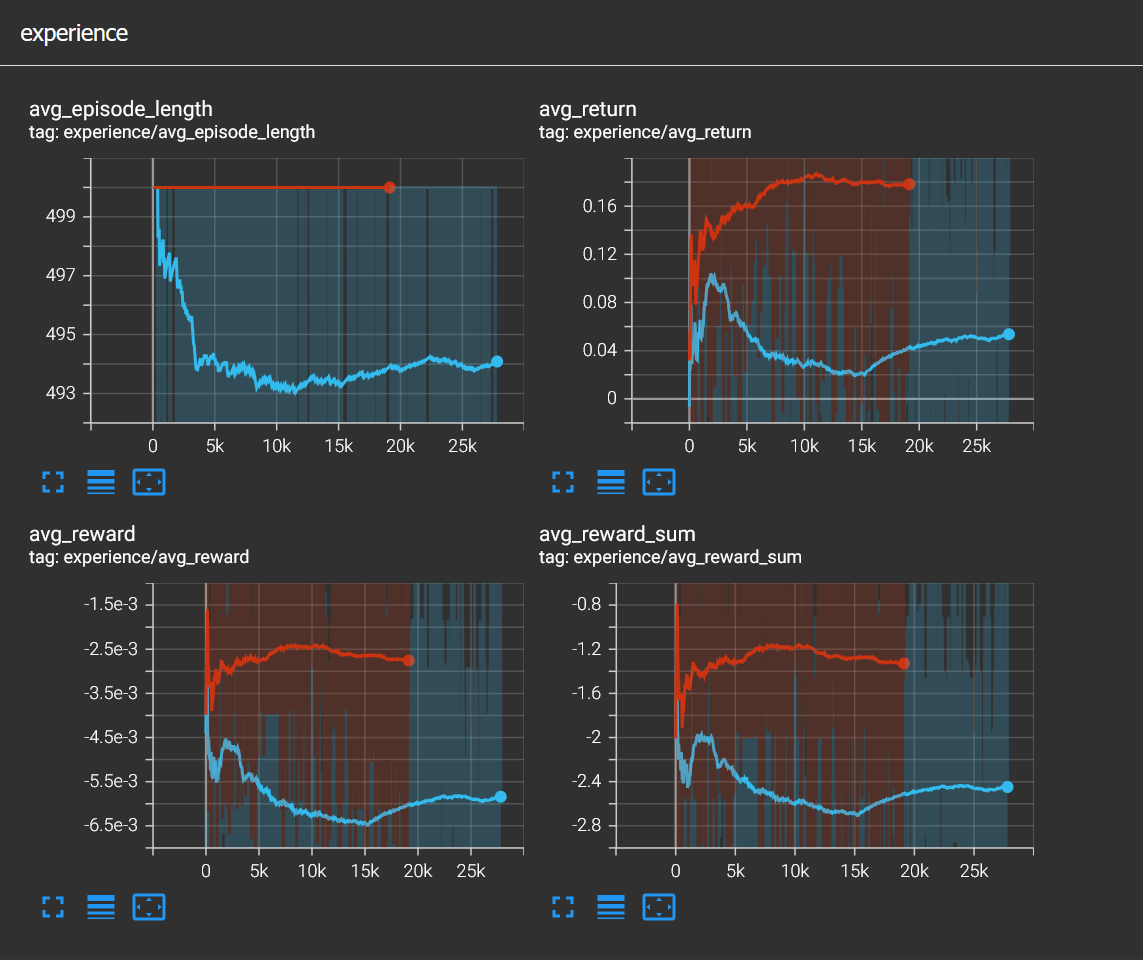
Above you can see the TensorBoard graphs showing when termination is at 3 hits and 2 hits. Cyan curve shows episode length drops a little as expected and rewards as well but at around 15k steps the agents starts to recover. As curriculum learning suggests cyan curve is trained on top of the red line.
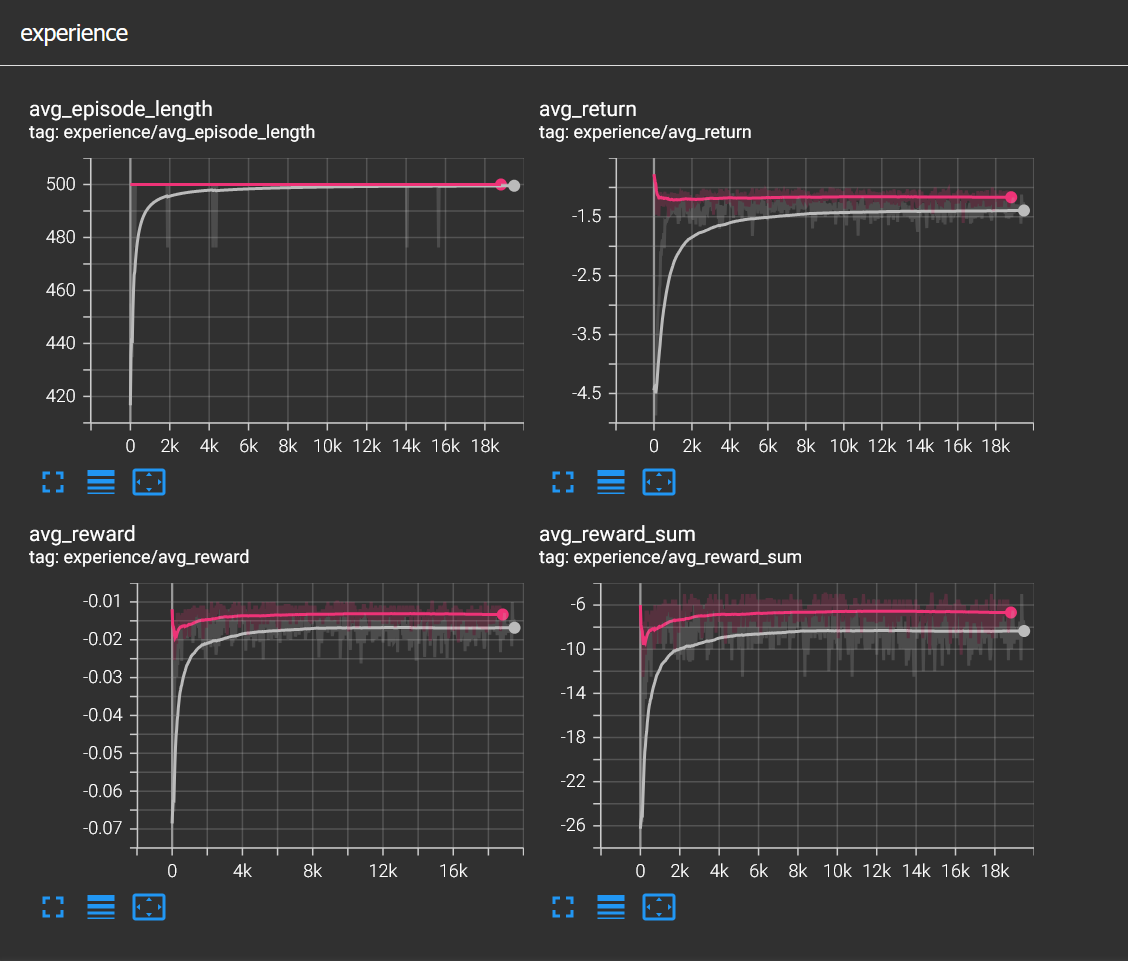
In the image above, TensorBoard graphs show comparison between different obstacle spawn frequencies. Pink curve represents spawn frequency=1 sec and gray curve represents spawn frequency=0.5 sec. You can see that episode length drops sharply below 420 but then recovers and stabilizes at 500. If miss reward was not removed, reward graphs would go up as well.
In the video above, you can see how 64 agents are running in parallel. It is quite fun and feels like watching CCTV. The agent is much better in my opinion, does not move frantically and also not get stuck in the corners. It still makes jerky moves but as I understand this may be inherent to how PPO samples discrete actions — rather than committing to the best action, it samples from the policy distribution, which introduces some natural variability. I think it was physically based the effect would be less visible and I might address in the next experiment.
