2026-05-15
Baby Steps
In this prototype I wanted to play more with physics, letting the agent physically interact with the world by learning how to use its weight, its limbs, and friction. I think this is where reinforcement learning really shines. In the previous prototypes one can argue that the problems would be solved by rule-based AI in a much more efficient way and I agree. Reinforcement learning is not a silver bullet. After working almost 2 decades in the games industry, I know that there is no silver bullet.
I started by designing a simple agent. 1 big body, 4 legs and 4 joints. I tried to give the agent a headstart by making the legs long and connecting them on the top corners so the center of mass is lower.
After making sure that the joints moved the legs as expected, it was time for giving it a brain that it deserved. I already had an idea for a curriculum for the agent. I was going to teach it to stand, and then face a direction and then finally walk to a location. I'll try to explain these in their respective parts.
Part 1: Standing up
It gets easier and easier as I collect more and more code with these projects. After writing some boilerplate code and moving files around, the agent had a brain. The actions I designed for the agent were controlling target velocity for each joint with a float action. And the observation space was the joint angle for each joint.
I spent a lot of time figuring out how to reset the agent's body. Since it was driven by physics, simply rotating and positioning didn't work. I needed to detach all the limbs, reset all the velocity on them and reattach. This approach worked fine.
I was expecting learning how to stand up to be fairly easy and quick. Based on my learnings from the previous experiments, the agent had all the information it needed. I also added a termination case which should have enforced it even more.
My first reward shaping was like below
if (Alignment < 0.9f) // Termination threshold
{
bHasFlipped = true;
}
float Reward = 0.0f;
float Alignment = FVector::DotProduct(Player->GetActorUpVector(), FVector::UpVector);
Reward += Alignment * 0.1f;
if (bHasFlipped)
{
Reward -= 1.0f;
}
OutReward = Reward;
This one failed to learn how to stand upright, even after 50k steps it was able to stand only for a couple seconds.

Then I made the termination case stricter and also changed the reward curve
if (Alignment < 0.95f) // Termination threshold
{
bHasFlipped = true;
}
float Reward = 0.0f;
float Alignment = FVector::DotProduct(Player->GetActorUpVector(), FVector::UpVector);
Reward += FMath::Pow(Alignment, 8.0f);
if (bHasFlipped)
{
Reward -= 1.0f;
}
OutReward = Reward;
This one was a great improvement over the previous one, agent could stand upright much longer. Though the training still took a very long time.
Part 2: Look at the target
Stand-up training took unusually long. After doing the previous experiments I thought I had developed some intuition. Given all the observations (joint angles), the agent should learn to stand still pretty quickly. It didn't happen. It took around 30k steps to stabilize. But I was happy with it regardless, since I could now start with the next lesson. For looking training I added a direction vector which was randomized every episode reset. I configured my curriculum to enable looking training when the episode length reached 250. 250 sounded like a good spot based on TensorBoard data.
After some minor adjustments, I left it to train for almost 8 hours. This was the longest training I have ever done. And Tensorboard graphs somehow looked good.
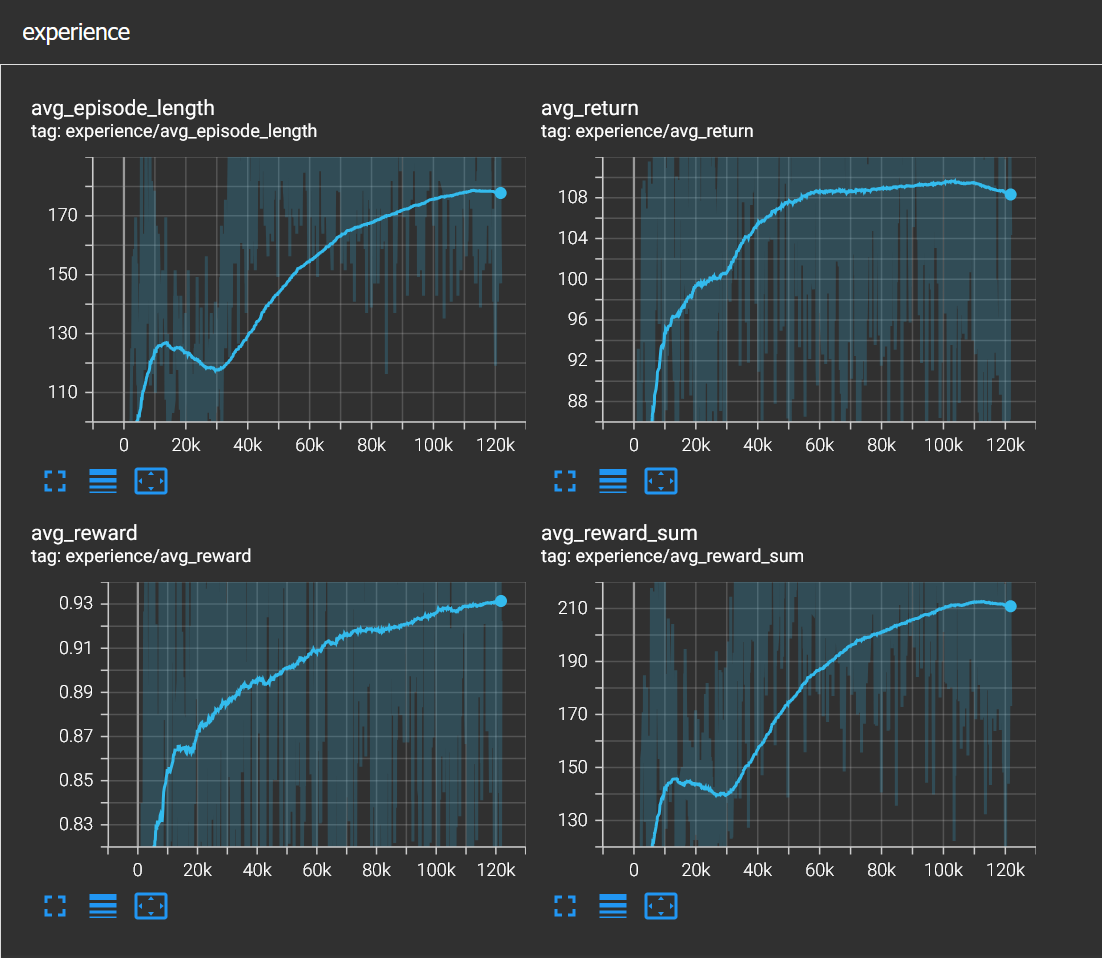
When I tried inference though, the agent behaviour was completely wrong. Even the standing behavior was gone and the agent was flipping after doing some fancy dance move.
I decided to make things easier for the agent. First I thought the cube colliders were disturbing the stability, so I changed them with capsule ones thinking that the legs would glide easier. I also made the legs shorter, moved them a bit further in the front and back. This actually made the balance base smaller but the agent didn't have giant legs that can trip it off easily. None of these really helped.
And then I got hit with a huge bug. I was feeding the network with joint twist values instead of swing values. It was very frustrating but also relieving at the same time. I immediately knew that this was the main problem. I fixed the functions that return joint angles and the standing training converged in less than 500 steps, yes five, zero, zero! My mind was blown. I was happy that my initial intuition was correct. I mean all the agent has to do was extending its legs anyways.
The looking curriculum kicked in very quickly since episode length passed 250 very fast. The agent also learned to look at a certain direction but there was always a bias, it was either clockwise or counterclockwise regardless of which direction was closer to the target.
As you can see, the agent has evolved a lot, both visually and physically. It was fun to work on visual stuff during long trainings. I didn't want to spend any more time on the turning bias problem and continued with the walking training.
Part 3: Walking
I implemented a reward shaping very similar to the previous tank example. Basically rewarding alignment with the target and distance delta. I also improved observation space by adding angular velocity for each leg. It worked well as I expected. I then disabled looking curriculum and it actually fixed the cw/ccw bias problem. I knew from the start that looking training was unnecessary. If the agent learned walking to the target eventually, looking is just an emergent behaviour to accomplish the task anyway. But it was great learning regardless, since I saw cw/ccw bias which I still don't understand why. My guess is that the network learns to steer to a certain direction early in the training and sticks with it forever. Maybe punishing extra movement might have resolved this.
I then disabled all curriculum and enabled walking training from the start. This worked much better actually since I had the termination case for vertical misalignment. The agent had to stand upright to proceed during the training anyways. And the agent learned to walk to the target.
I love that the agent has developed this cute gallop but I was not satisfied with the gait. The agent relied on one front and one rear leg on opposite sides. To turn right it used rear-left(or rear-right) leg and to turn left it used front-right(or front-left) leg. And the other two legs were used mostly for balance. Honestly I think this is a great strategy given that the agent only observes joint swing angle and angular velocity for each leg. I then played around with physics config a little. Added angular and linear damping to legs and also changed the physics material to rubber, which had higher friction factor. I think it helped with speed and stability but not with the gait.
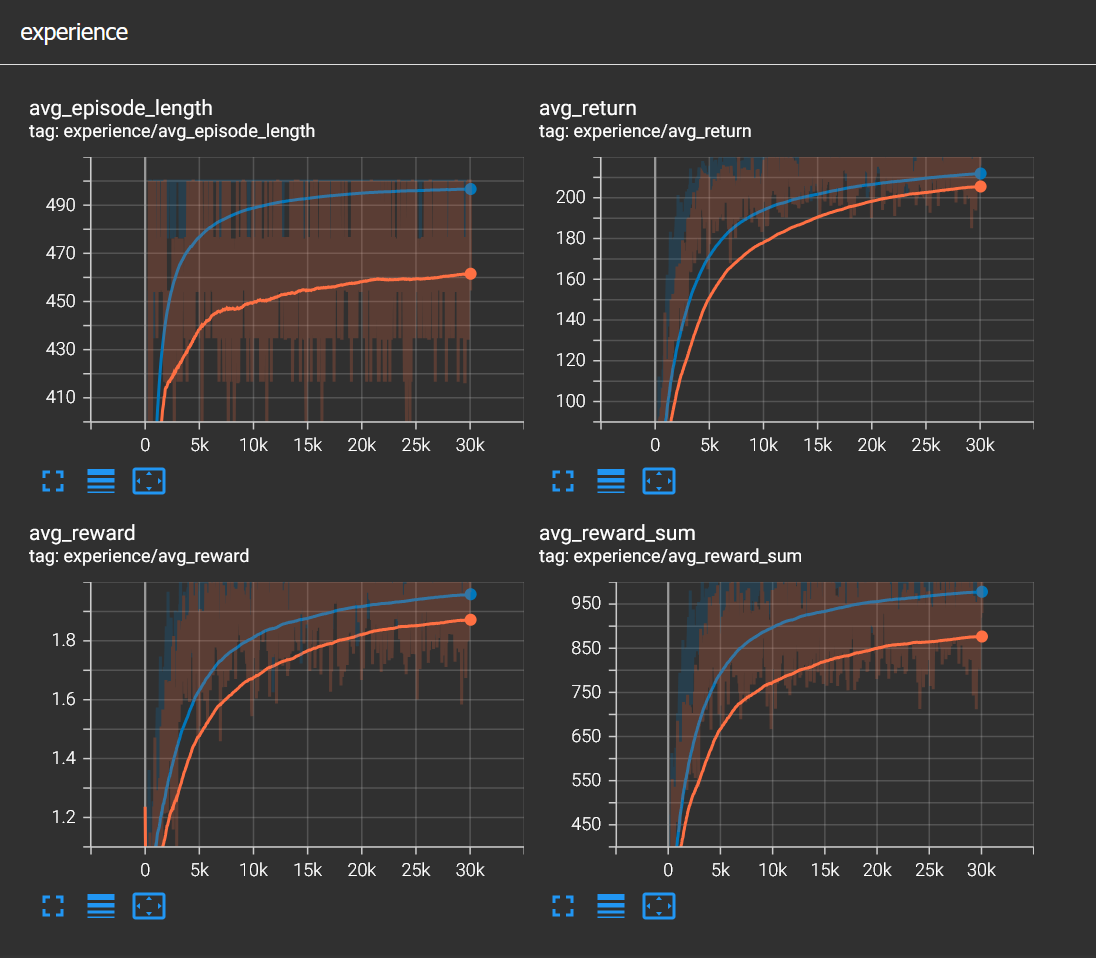
I was already satisfied with the result but I wanted to see if I could improve it somehow. I wanted to add some more observations, this time contact information for each leg. I fed the network with 4 booleans, representing contact information for each leg. And more importantly I added a small negative reward of -0.01 on every tick to increase urgency. The gait has changed and the cute gallop disappeared. And stability has improved a lot. You can see in the image below how average episode length climbed when contact information is observed. At this point it is a matter of taste which agent looks better. If you want a cute agent, then probably the first one and if you want an agent that is more stable, the second one is the way to go.
Final Words
I'm quite happy with how this experiment turned out. I learned a lot about physics and how chaotic it can get. I also developed more intuition about reinforcement learning.
You can find the source files in this github link.
